Over the course of the last few versions, PostgreSQL has introduces all kinds of background worker processes, including workers to do various kinds of things in parallel. There are enough now that it’s getting kind of confusing. Let’s sort them all out.
You can think of each setting as creating a pool of potential workers. Each setting draws its workers from a “parent” pool. We can visualize this as a Venn diagram:
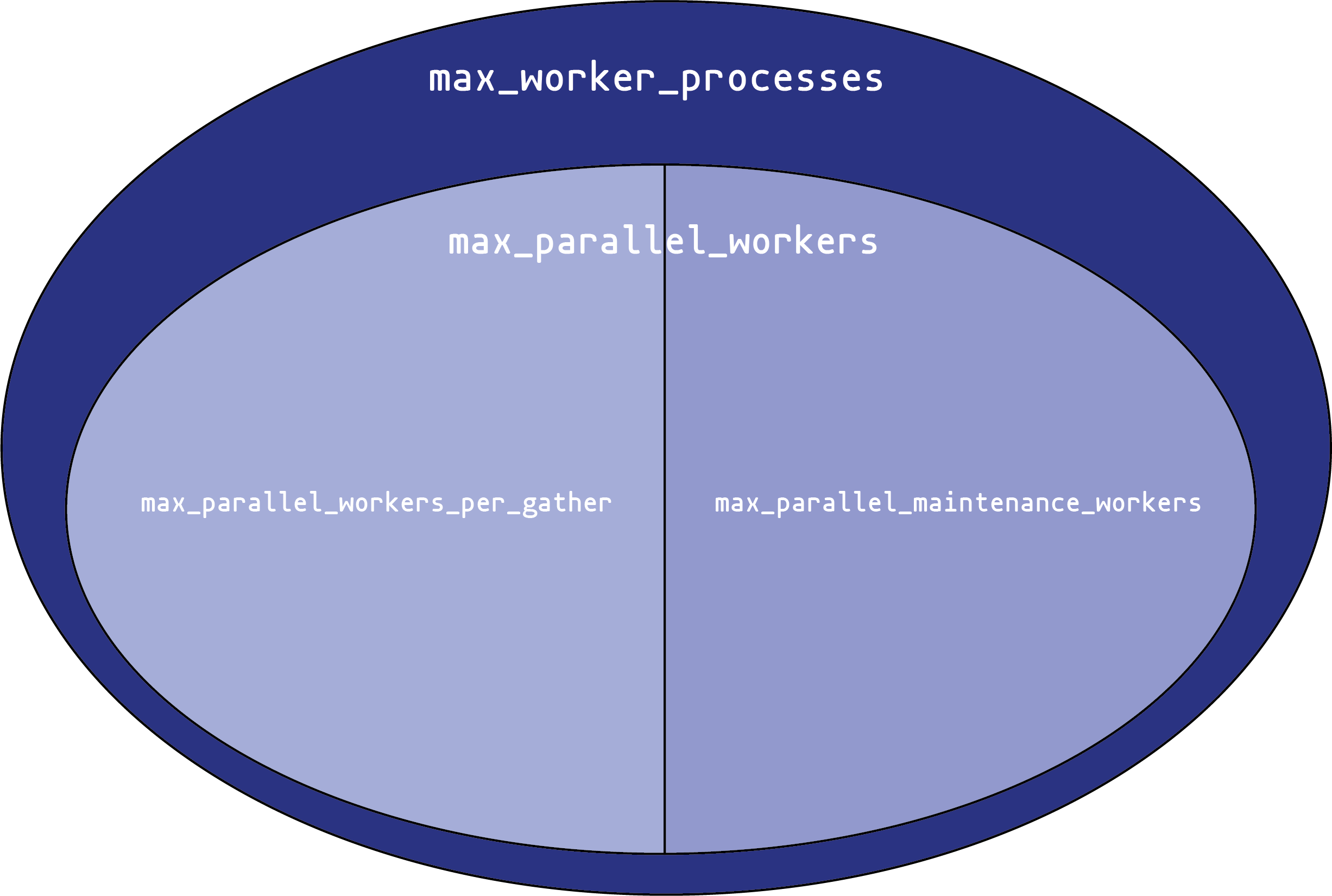
max_worker_processes sets the overall size of the worker process pool. You can never have more than that many background worker processes in the system at once. This only applies to background workers, not the main backend processes that handle connections, or the various background processes (autovacuum daemon, WAL writer, etc.) that PostgreSQL uses for its own operations.
From that pool, you can create up to max_parallel_workers parallel execution worker processes. These come in two types:
-
Parallel maintenance workers, that handle parallel activities in index creation and vacuuming.
max_parallel_maintenance_workerssets the maximum number that can exist at one time. -
Parallel query workers. These processes are started automatically to parallelize queries. The maximum number here isn’t set directly; instead, it is set by
max_parallel_workers_per_gather. That’s the maximum number of processes that onegatherexecute node can start. Usually, there’s only onegathernode per query, but complex queries can use multiple sets of parallel workers (much like a query can have multiple nodes that all usework_mem).
So, what shall we set these to?
Background workers that are not parallel workers are not common in PostgreSQL at the moment, with one notable exception: logical replication workers. The maximum number of these are set by the parameter max_logical_replication_workers. What to set that parameter to is a subject for another post. I recommend starting the tuning with max_parallel_workers, since that’s going to be the majority of worker processes going at any one time. A good starting value is 2-3 times the number of cores in the server running PostgreSQL. If there are a lot of cores (32 to 64 or more), 1.5 times might be more appropriate.
For max_worker_processes, a good place to start is to sum:
max_parallel_workersmax_logical_replication_workers- And an additional 4-8 extra background worker slots.
Then, consider max_parallel_workers_per_gather. If you routinely processes large result sets, increasing it from the default of 2 to 4-6 is reasonable. Don’t go crazy here; a query rapidly reaches a point of diminishing returns in spinning up new parallel workers.
For max_parallel_maintenance_workers, 4-6 is also a good value. Go with 6 if you have a lot of cores, 4 if you have more than eight cores, and 2 otherwise.
Remember that every worker in parallel query execution can individually consume up to work_mem in working memory. Set that appropriately for the total number of workers that might be running at any one time. Note that it’s not just work_mem x max_parallel_workers_per_gather! Each individual worker can use more than work_mem if it has multiple operations that require it, and any non-parallel queries can do so as well.
Finally, max_parallel_workers, max_parallel_maintenance_workers, and max_parallel_workers_per_gather can be set for an individual session (or role, etc.), so if you are going to run an operation that will benefit from a large number of parallel workers, you can increase it for just that query. Note that the overall pool is still limited by max_worker_processes, and changing that requires a server restart.